-
尊龙凯时(中国)官方网站传统4D雷达多选定多芯片级联决议-尊龙凯时人生就是博·「中国」官方网站
发布日期:2026-01-07 07:34 点击次数:59
作家:毛烁
当自动驾驶的竞争从L2+级向L3级迈进的要害节点,其靠近的挑战时常不再只来自算法自己,而是被三堵“工程墙”所按捺——算力能效范围、感知本钱弧线,以及车内通讯架构的割裂。
在CES 2026上,TI在拉斯维加斯亮相了其新的居品组合,直指这三堵“工程墙”,以可量产、可落地的决议,逐项击穿功耗、本钱与架构瓶颈。
01 “去液冷画”旅途:用能效跨过“算力墙”
跟着软件界说汽车(SDV)的架构捏续下千里,区域适度器(Zonal Control)与中央计较单位的会通,还是从观点选拔演变为工程实践。但随之而来的,是算力蚁集带来的功耗与散热压力,正在反向制约架构自己的演进。
在刻下的主流决议中,高性能SoC时常通过通用GPU堆叠算力。这全部径加快推高了芯片功耗,迫使整车系统引入液冷决议。
然而,关于定位世界商场、强调本钱可控性的车型而言,液冷系统不仅意味着BOM本钱飞腾,更触及到整车结构、可靠性与供应链复杂度的系统性抬升。事实上,这已成为SDV 普及经过中的隐性门槛。
TI这次在CES 2026上重心展示的TDA5高性能SoC系列(后文简称“TDA5”),恰是针对这一结构性矛盾,推出的工程解法。
期间层面上,TDA5并未沿用“通用GPU堆料”的主流道路,而是回到了TI最为老到的地方——DSP 架构下的能效极限挖掘。
TDA5的中枢在于集成的TI C7 神经惩处单位(NPU)。这一惩处单位围绕矩阵计较与当代AI算法负载进行深度定制,对包括Transformer推理、BEV俯视图在内的车载感知与会通任务进行了针对性优化。
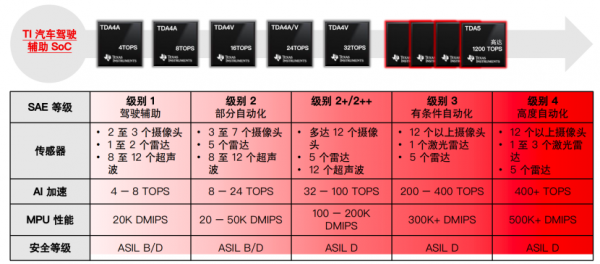
这种架构选拔,奏凯体目下能效打算上。TDA5在官方透露的数据中,收场了跨越24 TOPS/W的能效水平。
换言之,在践诺同等第别AI任务时,其功耗权贵低于依赖大范围GPU并行的决议。在典型的 L2+级应用场景(算力需求约400 TOPS) 下,TDA5以致不错开脱液冷系统,仅通过风冷或被迫散热收场始驱逐实首先。
在架构层面,TDA5的另一项要害期间上风,是引入了Chiplet(芯粒),并复古行业圭臬的UCIe互承接口。模块化算力单位的引入,使得扫数这个词平台的算力确立不再被单一SoC所固化,而是不错在10TOPS到1200TOPS的区间内按需推广。
从应用成果来看,这一设想对OEM的兴致,一方面在于性能的教化自己。另一方面则是,在消逝套软件与系统架构下,车企不错通过增减Chiplet数目,无邪隐敝从初学级“前视一体机”到旗舰级“L3中央计较平台”的不同居品方法,无需为每一档车型孤立吝惜硬件平台。
在“去液冷化”的工程想路下,TDA5 推行上把高性能计较再行拉回到了主流车型可承受的系统范围之内。
02 降体积、降BOM、保细节 4D成像雷达的工程校阅
在L3级自动驾驶的感知链路中,4D成像雷达因其具备高度(Elevation)探伤才略,能灵验分裂路面静止物(如井盖、桥梁)与的确不容物,被视为要害传感器。运筹帷幄词,传统4D雷达多选定多芯片级联决议,导致模组体积强大、本钱精熟,难以大范围部署。
TI这次展示的AWR21884D成像雷达收发器(后文简称“AWR21884D”),则对雷达方法进行了校阅。
TI欺诈其在射频CMOS工艺上的上风,在单颗芯片内集成了8个放射通说念和8个罗致通说念。这一打算意味着,仅需一颗AWR2188,即可达到往日两颗传统芯片级联智力收场的分辨率。
另外,该芯片的性能打算也有了大幅跃升,其ADC采样率达66 MSPS,线性调频脉冲斜率达到266 MHz/μs。在典型工况下,该芯片在高速场景中可收场对远距离车辆办法的厚实探伤,并在近距离多车并行或紧邻行驶时,保捏弥散的分辨率以分裂相邻办法,为复杂交通环境下的雷达感知提供了更可靠的物理基础。
AWR2188的价值,并不啻于雷达本色性能的教化。的确的变化,发生在系统架构层面。
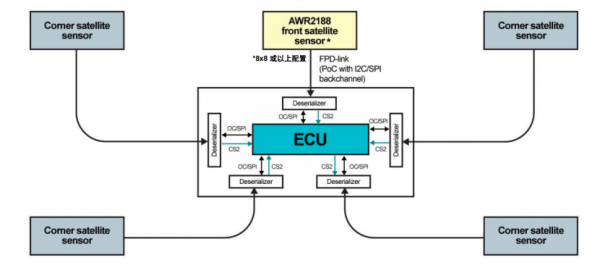
围绕AWR2188,TI选定了“卫星雷达架构(Satellite Architecture)”的设想想路。在这一架构中,散播在车身各处的雷达节点不再承担复杂的点云生成与办法级惩处任务,而是追想为转变当的感知前端。
这其中,AWR2188复古将未压缩的原始雷达数据(Raw Data)奏凯输出,并通过高速接口流式传输至中央计较单位。
这种“强中央、轻旯旮”的单干表情,在系统层面带来了两重奏凯纳益。
在物理与工程层面,单芯片8Tx8Rx的高度集成,使雷达模组体积权贵缓慢,更易于镶嵌车门、翼子板、保障杠边角等受限位置。同期,减少芯片数目也灵验裁减了模组BOM本钱与安装复杂度。
在算法与感知层面,中央SoC奏凯基于雷达、录像头等传感器输出的原始数据进行长入惩处,比较传统以办法落幕为输入的“后会通”决议,新决议能够在系统层面保留更多时序与空间细节信息。由此带来的变化是,在“鬼探头”、低矮静止不容物,以及多办法相互遮盖等复杂场景中,感知算法对细节变化与绝顶活动的识别愈加厚实。
03 买通“通讯孤岛”:以太网蔓延至车身“神经末梢”
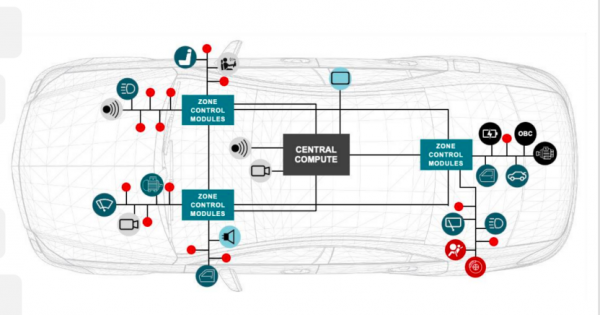
在整车电子电气架构中,通讯麇集的碎屑化始终是被忽视却难以侧目的问题。尽管千兆以太网还是成为车内主干麇集的事实圭臬,但在车窗、座椅、灯光等车身旯旮节点,CAN、LIN等传统总线仍然占据主导地位。这一割裂的采聚集构,使中央计较单位无法对旯旮践诺器进行奏凯、高速的打听,必须依赖多级网关完成公约休养,客不雅上造成了无数“通讯孤岛”。
TI这次展示的DP83TD555J-Q1 10BASE-T1S以太网PHY(简称DP83TD555J-Q1),是针对这一结构性问题冷落的补全决议,办法是将以太网才略蔓延至车身结尾节点。
在期间收场上,DP83TD555J-Q1的要害设想在于,在PHY里面集成了以太网媒体打听适度器(MAC)。
其实,在现存车身适度架构中,无数低本钱MCU并不具备以太网MAC接口,这也所以太网难以向旯旮普及的进军原因。通过将MAC下千里至PHY,使这些MCU只需通过通用的SPI 接口,便可奏凯接入DP83TD555J-Q1的10BASE-T1S以太网,从而裁减旯旮节点接入以太网的门槛。
在功能层面,该芯片同期复古数据线供电(PoDL),通过一双双绞线即可同期完成数据与电力传输。更具系统兴致的是,DP83TD555J-Q1复古纯正(Tunneling)机制,可将CAN、LIN等传统总线数据封装为以太网帧进行传输,使既有车身麇集能平滑接入以太网体系。
从应用落幕来看,10BASE-T1S向车身旯旮节点的下千里,意味着以太网从主干麇集蔓延至整车“神经末梢”。在这一架构下,工程师不错基于IP地址奏凯寻址并适度车窗电机、座椅模块、氛围灯等践诺器,减少中间网关带来的公约休养与时延支出。
更进军的是,这种端到端的长入通讯表情,使软件界说汽车不再停留在中央计较平台层面,而是造成了的确隐敝感知、计较与践诺的闭环体系。
从这一层面看,改日OTA更新,约略具备了直斗争达车身每个践诺节点的工程基础。
04 写在终末
TI在CES 2026上展示的这三块“拼图”——TDA5、AWR2188、与DP83TD555J-Q1,逻辑丝丝入扣。
TDA5以极致能效为中枢,压低了蚁集式计较在功耗、散热与系统本钱上的门槛;AWR2188则借助卫星雷达架构,将高阶感知从“堆硬件”转向“重单干”,缓解了体积、复杂度与感知精度之间的始终张力;而DP83TD555J-Q1的下千里,则补王人了车身旯旮节点的通讯才略,使蚁集式计较与散播式践诺造成的确连贯的麇集体系。
在L3级自动驾驶行将迎来量产大考的要害阶段,行业所靠近的已不再是“能否收场”,而是“能否范围化落地”。TI这次给出的,约略是一套更齐备的系统级解法。
某种进度上,TI展出的这些以工程为起点的革命尊龙凯时(中国)官方网站,约略恰是刻下车企需要的谜底。